01
一个反直觉的判断
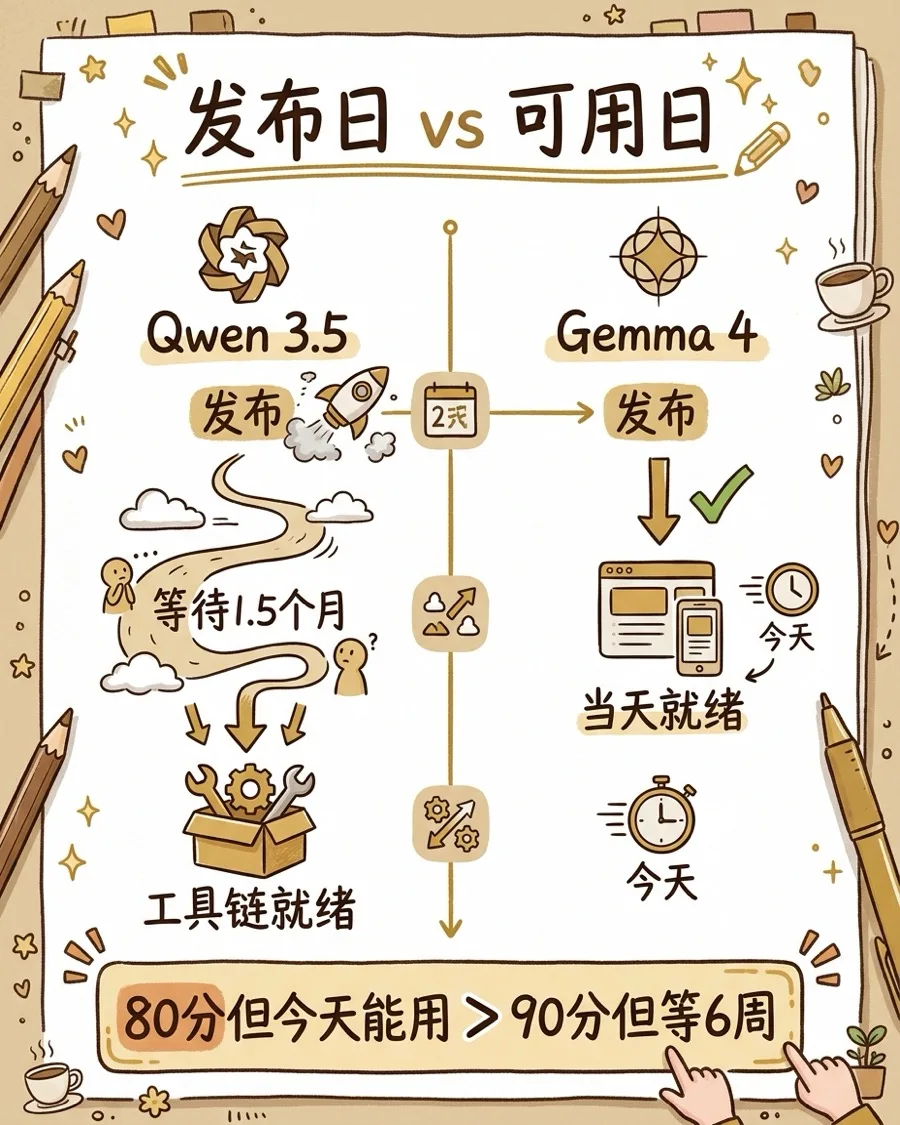
前几天Google DeepMind发布了Gemma 4,开源,Apache 2.0许可证,31B参数的版本在Arena排名里冲到了开源模型第三。
如果你只看数据,会觉得这是一个很标准的「又一个开源模型发布」的故事。每个月都有新模型刷榜,大家早就麻木了。
但AI研究机构Ai2的Nathan Lambert写了一篇很有意思的分析。他是做后训练和RLHF的一线研究员,长期跟踪开源模型生态。
他的核心判断:Gemma 4能不能成功,跟跑分几乎没有关系。上下浮动5-10%,不影响结果。
这话听起来反直觉。我们每天看到各种模型发布,标题都是「SOTA」「全面超越」「排行榜第一」。
好像跑分高就是好模型,跑分低就该淘汰。
但如果你真的在用开源模型做产品,你会知道事情不是这样的。